GCP Data & Analytics
Petabyte-scale analytics in seconds — powered by the same infrastructure that analyzes Google Search data.
Analytics at Google Scale
BigQuery fundamentally changed the economics of data analytics. Traditional data warehouses force painful capacity planning — guess wrong and you either waste money on idle cores or watch critical queries timeout during peak hours. BigQuery eliminates this trade-off entirely with a serverless architecture that scales compute dynamically per query, charges by data scanned, and returns results from petabyte datasets in seconds.
We build comprehensive data analytics platforms on GCP that span the entire intelligence lifecycle — from raw data ingestion through transformation, modeling, and visualization. By combining BigQuery with Dataflow (Apache Beam), Pub/Sub for streaming, Dataproc for Spark workloads, and Looker for enterprise BI, we deliver self-service analytics that democratize data access across your entire organization.
Our data engineering practice on GCP is built around cost optimization as a first principle. BigQuery's pricing model rewards efficient query design and proper data organization. We implement partitioning, clustering, and materialized views that can reduce query costs by 90% compared to naive table scans — ensuring you are not penalized for having large datasets.
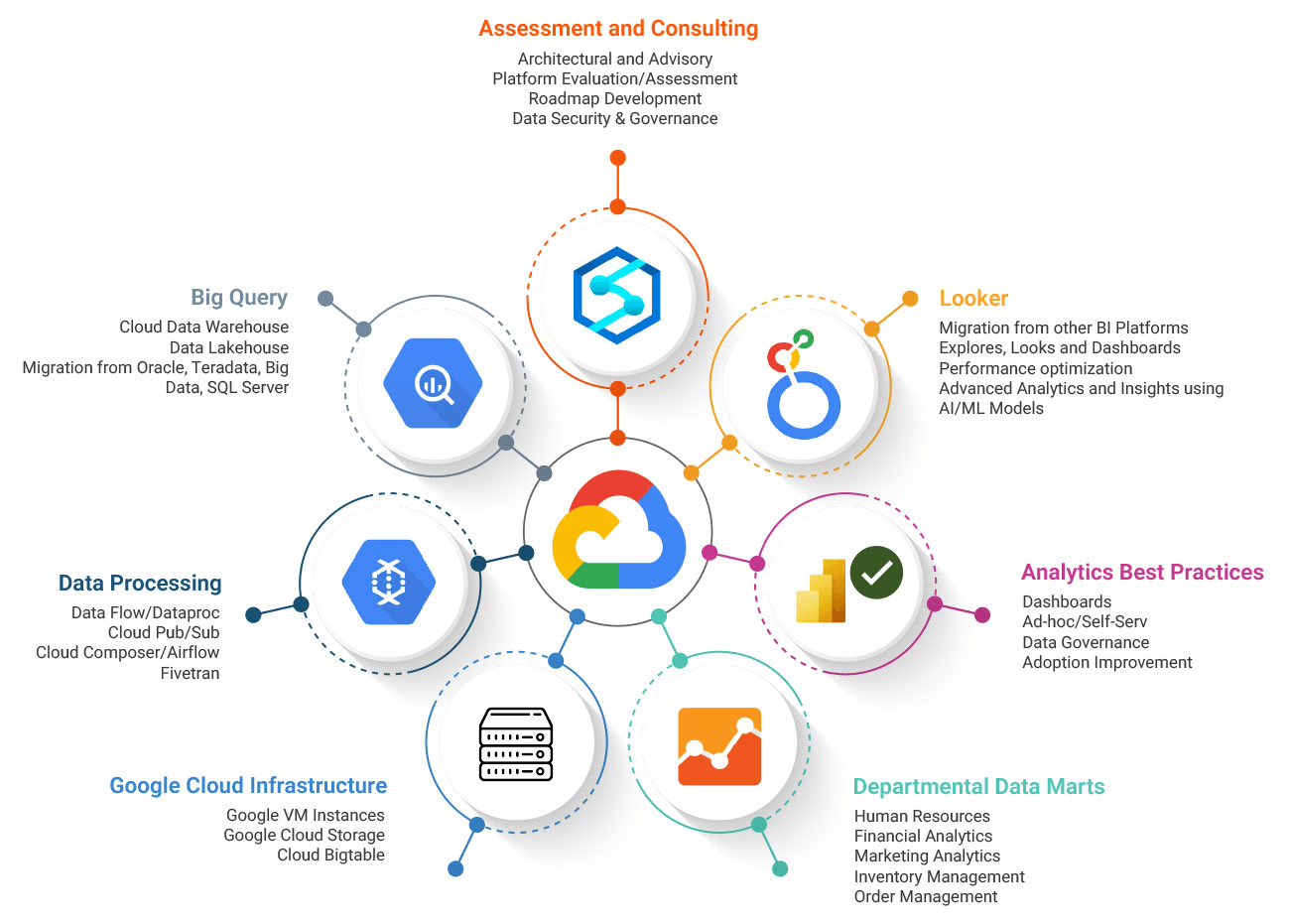
When BigQuery Delivers Decisive Advantage
Scenarios where GCP data analytics outperforms traditional approaches.
Warehouse Cost Explosion
Your Snowflake or Redshift bill has grown to six figures monthly, but reducing compute provisioning causes critical dashboards to timeout. BigQuery's serverless model eliminates this tension — you pay per query, not per hour of cluster uptime.
Real-Time Analytics Demand
Your business requires live dashboards that update within seconds of an event — not hourly batch refreshes. BigQuery's streaming insert API and Pub/Sub integration enable sub-second data availability for real-time operational intelligence.
Multi-Cloud Data Access
Your data is fragmented across AWS S3, Azure Blob Storage, and on-premises databases. BigQuery Omni queries data in-place across clouds without data movement — providing a single SQL interface to your entire multi-cloud data estate.
Data Democracy Paralysis
Only your three senior data engineers can write SQL queries, creating a bottleneck where 50 business stakeholders queue requests for weeks. Looker's modeled exploration layer enables non-technical users to answer their own questions without writing code.
Data Analytics Capabilities
End-to-end data platform services built on GCP's analytics stack.
Designing highly optimized BigQuery datasets that minimize query costs while maximizing performance. We implement partitioning strategies, clustering keys, and materialized views that reduce per-query costs by up to 90% — turning BigQuery from 'expensive if misused' into 'dramatically cheaper than alternatives.'
Building event-driven data architectures that ingest millions of events per second and make them queryable within seconds. We design streaming pipelines using Pub/Sub for ingestion and Dataflow (Apache Beam) for real-time transformation — enabling operational dashboards, alerting systems, and ML feature stores that operate at streaming speed.
Deploying Looker as the enterprise semantic layer — a centralized, governed business logic model that ensures every team queries data using consistent metric definitions. Looker's LookML modeling language defines business rules once and enforces them everywhere — eliminating the 'different numbers from different reports' problem permanently.
Implementing reliable, monitored data pipeline orchestration that ensures every dataset is fresh, accurate, and available when your business needs it. We design fault-tolerant pipelines with automated quality checks, retry logic, and alerting that prevent bad data from reaching downstream consumers.
Data Platform Engineering
Building governed, high-performance analytics platforms from ingestion through visualization.
Requirements & Strategy
We identify the critical business questions, map them to required data sources, and design the target architecture. We select the optimal GCP services for each layer — Pub/Sub vs. Datastream for ingestion, Dataflow vs. Dataproc for processing, BigQuery for warehousing, Looker vs. Looker Studio for visualization.
Ingestion & Storage
We build automated data pipelines ingesting from your source systems — databases, SaaS APIs, event streams, and file drops — into BigQuery and Cloud Storage. We implement the medallion architecture (raw → cleaned → curated) with proper partitioning and access controls at each tier.
Transformation & Modeling
We transform raw data into analytically optimized models using dbt or Dataflow. We build the LookML semantic layer in Looker defining consistent business metrics, calculated fields, and dimensional hierarchies that govern how every consumer interprets the data.
Visualization & Enablement
We deploy Looker dashboards, configure scheduled data deliveries, and train business analysts to build their own explorations. We establish governance for dashboard lifecycle management, access controls, and usage monitoring to ensure the platform scales sustainably.
Industry Applications
Google Cloud solutions built for the world's most demanding data, ML, and infrastructure challenges.
Ad Tech & Digital Marketing
Building real-time advertising analytics pipelines ingesting billions of ad impression events daily through Pub/Sub and Dataflow into BigQuery — enabling campaign performance optimization with sub-minute data freshness and anomaly detection alerting for budget overspend.
Supply Chain & Logistics
Deploying IoT sensor analytics on BigQuery processing GPS telemetry from 50,000 fleet vehicles — providing real-time route optimization, predictive maintenance alerting, and fuel efficiency analysis with Looker dashboards accessible to logistics coordinators on mobile devices.
Financial Services & Trading
Engineering tick-level market data analytics on BigQuery's columnar storage — enabling quantitative analysts to backtest trading strategies across 10 years of historical tick data (trillions of rows) with sub-minute query response times at a fraction of the cost of dedicated HPC clusters.
Related Services

GCP AI & Machine Learning
Building and deploying production ML models using Vertex AI and Google's AI research infrastructure.

Google Cloud Consulting & Strategy
Architecting cost-efficient, open-source-first cloud strategies on Google Cloud Platform.

AWS Data & Analytics
Transforming raw operational data into actionable business intelligence using AWS.
Azure Data & Analytics Services
Unlocking powerful insights using modern big data architectures on Microsoft Azure.
GCP AI & Machine Learning
Building and deploying production ML models using Vertex AI and Google's AI research infrastructure.
Google Cloud Consulting & Strategy
Architecting cost-efficient, open-source-first cloud strategies on Google Cloud Platform.
AWS Data & Analytics
Transforming raw operational data into actionable business intelligence using AWS.
Azure Data & Analytics Services
Unlocking powerful insights using modern big data architectures on Microsoft Azure.