AWS Data & Analytics
From fragmented data silos to real-time, executive-ready intelligence — at petabyte scale.
Turning Silos into Strategic Intelligence
Organizations are drowning in data but starving for insights. Customer interactions, operational logs, financial transactions, and IoT telemetry are scattered across dozens of disconnected systems — rendering it impossible to get a unified view of business health without massive manual effort involving spreadsheets, email chains, and quarterly data reconciliation exercises that nobody trusts.
We engineer scalable data lakes, real-time streaming pipelines, and high-performance data warehouses on AWS. By consolidating data silos into a governed, queryable central platform, we empower executive teams to make evidence-based decisions in minutes rather than waiting weeks for a manually compiled report that is already outdated by the time it reaches the boardroom.
Our data engineering practice goes beyond infrastructure — we focus obsessively on data quality, governance, and accessibility. The most sophisticated Redshift cluster in the world is worthless if your business analysts cannot write a query against it. We design data models and semantic layers that make complex datasets accessible to non-technical stakeholders through self-service BI tools.

When Your Data Strategy Needs Engineering
These patterns reveal that your data architecture is limiting business intelligence.
Conflicting Reports
Marketing reports quarterly revenue as $12M while Finance reports $10.8M. Both teams are pulling from different databases with different calculation logic, different fiscal calendar definitions, and neither can explain the discrepancy without a two-week investigation.
Week-Long Report Generation
Your BI team spends 4-5 days every month manually extracting data from Salesforce, joining it with inventory data from SAP, cross-referencing it with Google Analytics exports, and pasting it all into Excel to produce a report that the CFO glances at for 90 seconds.
Database Performance Collapse
Running analytical queries directly against your production transaction database is causing application timeouts for end users. Your DBA has started scheduling heavy reports at 2 AM to avoid impacting customers, but even those are timing out on larger datasets.
Regulatory Data Requirements
New compliance regulations require you to demonstrate full data lineage — proving exactly where every number in your financial reports originated, how it was transformed, and who accessed it. Your current spreadsheet-based analytics cannot provide this auditability.
What We Deliver
Enterprise-grade AWS capabilities with measurable, outcome-driven results for every engagement.
Serverless Data Lakes
Centralized, infinitely scalable repositories that allow you to store and query exabytes of structured, semi-structured, and unstructured data without managing a single server. We design S3-based data lake architectures with proper partitioning, compression, and access controls that reduce storage costs by 80% compared to traditional database warehousing.
Modern Data Warehousing
High-performance enterprise analytics environments built on Amazon Redshift that deliver sub-second query response times on datasets containing billions of rows. We design the physical data model, optimize sort keys and distribution styles, and implement materialized views that pre-compute expensive aggregations your executives query daily.
Real-Time Streaming Pipelines
Ingesting and processing millions of events per second for immediate operational intelligence. We build streaming architectures that transform your data from batch-delayed to real-time — enabling fraud detection in milliseconds, live customer behavior dashboards, and automated alerting on business-critical metric deviations.
Data Governance & Quality
Implementing the organizational and technical frameworks that ensure your data remains trustworthy, discoverable, and compliant as volumes scale. Without governance, data lakes inevitably become data swamps — we prevent this by enforcing schema evolution policies, automated quality checks, and comprehensive data cataloging from day one.
Data Engineering Process
Building resilient, governed pathways from raw operational data to actionable executive insights.
Strategy & Discovery
We identify the exact business questions your executives need answered, then trace those questions backwards to the source systems containing the required data. This demand-driven approach ensures we build pipelines that directly serve decision-making rather than ingesting data for its own sake.
Ingestion & Integration
We build automated batch and streaming data pipelines that extract data from your operational systems (CRMs, ERPs, SaaS APIs, databases, log files) and land it reliably in the AWS data platform. Every pipeline includes error handling, retry logic, and dead-letter queuing.
Transformation & Modeling
Raw ingested data is cleaned, deduplicated, type-cast, and modeled into analytical schemas using dbt (data build tool) or AWS Glue. We implement slowly-changing dimensions, incremental processing, and automated testing to guarantee data accuracy at every transformation step.
Visualization & Enablement
The modeled data is exposed through Amazon QuickSight dashboards, API endpoints, or direct SQL access — depending on the consumer profile. We train business analysts to build their own reports, establish dashboard governance, and configure automated alert notifications on KPI threshold breaches.
Industry Applications
Our AWS strategies are aggressively tailored to the unique regulatory, competitive, and operational realities of your specific industry.
Retail & Consumer Goods
Building real-time inventory visibility dashboards that unify POS transaction data, warehouse management system feeds, and supplier shipment tracking into a single platform — enabling automated reorder triggers and reducing stockout events by 35% across 500+ retail locations.
Financial Services & Insurance
Engineering a regulatory reporting data warehouse on Redshift that aggregates transaction data from 12 different banking systems, applies standardized GAAP calculations, and generates automated compliance reports for the Federal Reserve with full data lineage auditability.
Media & Entertainment
Deploying real-time streaming analytics on viewer engagement data using Kinesis and Flink, enabling content recommendation engines to update viewer profiles within seconds of playback events — increasing average watch time by 22% through hyper-personalized content surfacing.
Related Services

AWS AI & Machine Learning
Deploying production-grade machine learning models and generative AI on AWS.

AWS Migration Services
Zero-downtime, secure migrations from on-premise or other clouds to AWS.
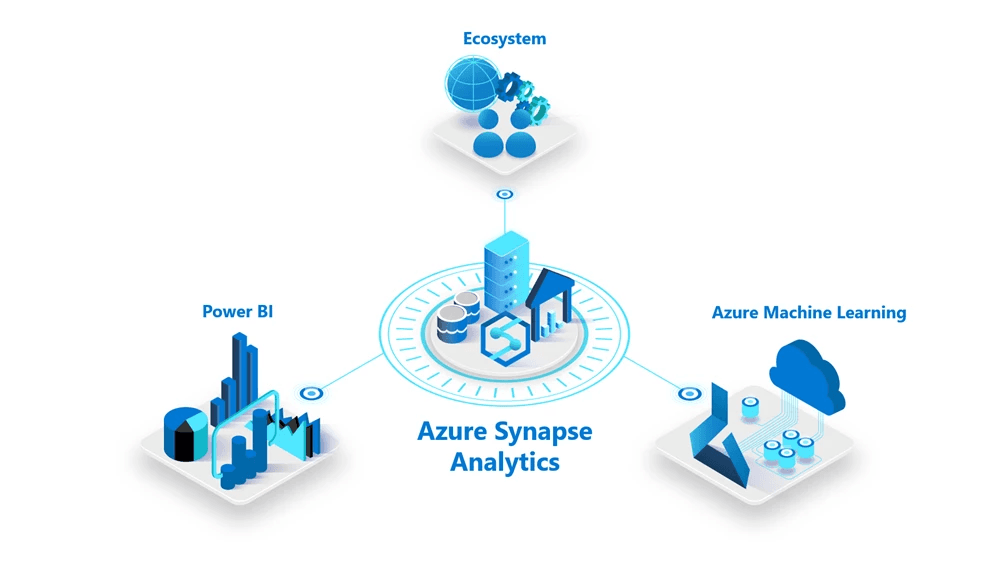
Azure Data & Analytics Services
Unlocking powerful insights using modern big data architectures on Microsoft Azure.
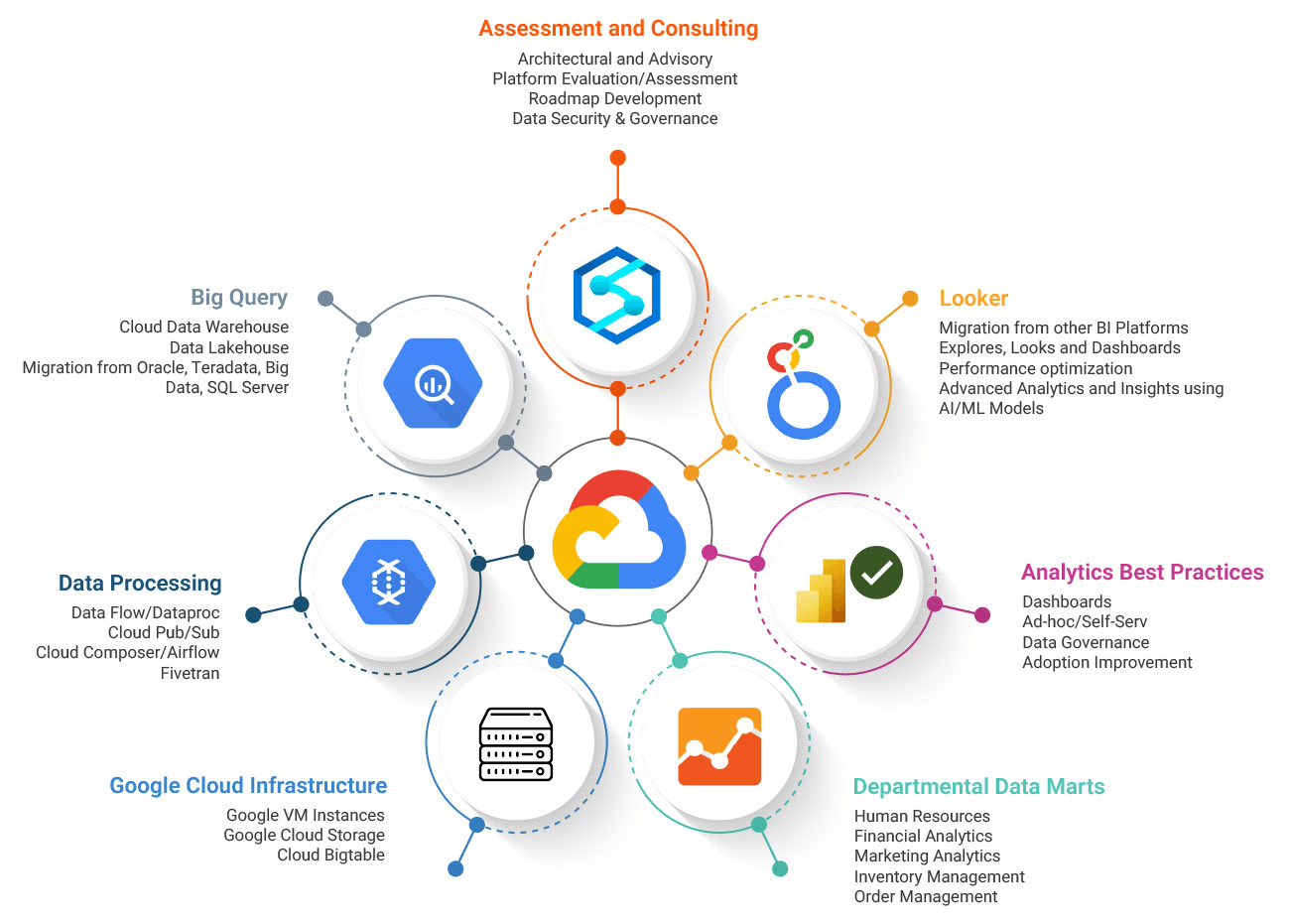
GCP Data & Analytics
Harnessing BigQuery's serverless architecture for petabyte-scale analytics and real-time intelligence.
AWS AI & Machine Learning
Deploying production-grade machine learning models and generative AI on AWS.
AWS Migration Services
Zero-downtime, secure migrations from on-premise or other clouds to AWS.
Azure Data & Analytics Services
Unlocking powerful insights using modern big data architectures on Microsoft Azure.
GCP Data & Analytics
Harnessing BigQuery's serverless architecture for petabyte-scale analytics and real-time intelligence.